When I landed my first tech jobs, I quickly realize that no amount of side projects, certifications, or online courses fully prepared me for professional reality. Indeed every company operates in its own unique ecosystem of tools, constraints, and engineering practices. For example I have worked with Banking systems running Hadoop clusters deployed with Cloudera. Startups relying entirely in the cloud. Teams swearing by Python while others champion R or Scala. Even when companies use the same language, their engineering practices can be worlds apart.
One team might have sophisticated CI/CD pipelines on GitHub, while another struggles with basic version control on Bitbucket. Sometimes the constraints get even more unexpected but still interesting. At my work with AXA Belgium, we could not use Docker containers for security reasons, period. This meant deploying an LLM application required other solutions like AWS Lambda instead of the straightforward Fargate approach we would have preferred. Not ideal, but it worked.
Here I want to share how we tackled some data and machine learning challenges at Sunrise. Our deployment strategies, our attempt at MLOps good practices, and the solutions we developed for our specific constraints. This is not a blueprint you should copy. It is simply the story I built there: how we approached technical challenges with their particular stack, requirements, and trade-offs.
What is sunrise by the way
Sleep apnea affects millions but remains poorly diagnosed—a condition that contributes to cardiac and metabolic diseases. Traditional diagnosis typically requires expensive sleep labs and overnight stays, creating barriers to access for many patients. Moreover, polysomnography required the patient to suit-up with a lot of instrument. Look by yourself.

from a marketing perspective this illustration is actually very compelling
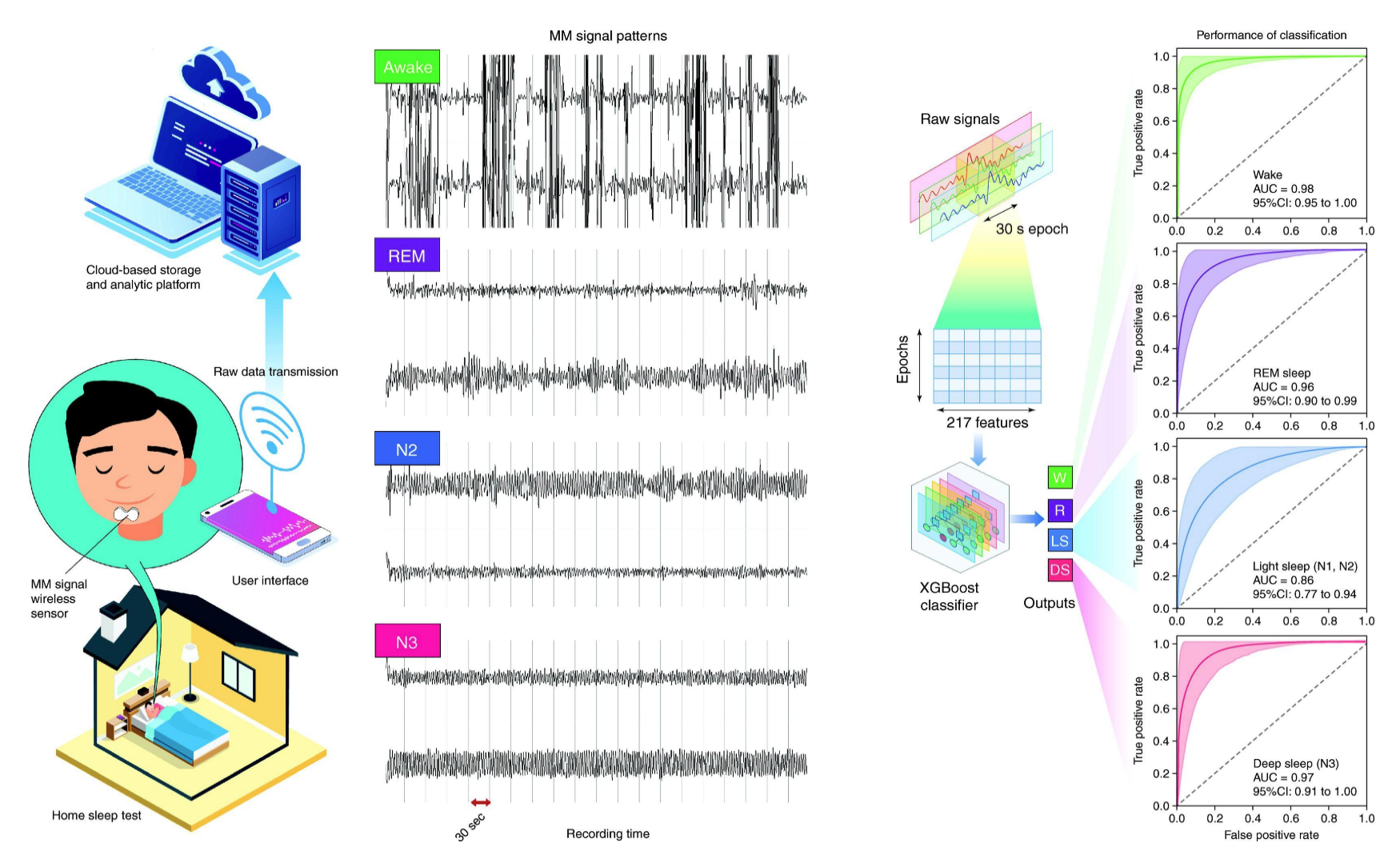
To address this challenge, Sunrise built their company around sleep medicine and AI, focusing on making sleep monitoring more accessible. Their approach is based on research showing that mandibular muscle contractions (MMC) can effectively monitor sleep quality and detect apneas. Specifically, they developed a small device that attaches to the chin and records these muscle contractions through gyroscopic data. This raw data is then processed by their algorithms to generate insights about sleep patterns and potential issues. Sunrise combines their monitoring device with a mobile app that enables at-home sleep assessment, where users receive reports detailing their sleep phases and clinical metrics after monitoring—information that was traditionally only available through lab-based studies. The result is a more accessible approach to sleep monitoring that users can implement from home. The model they used is a simple XGBoost that classify each 30-seconds period of sleep into: Awake, Deep sleep, Light sleep, REM sleep.
The starting point
The first infrastructure looked like this
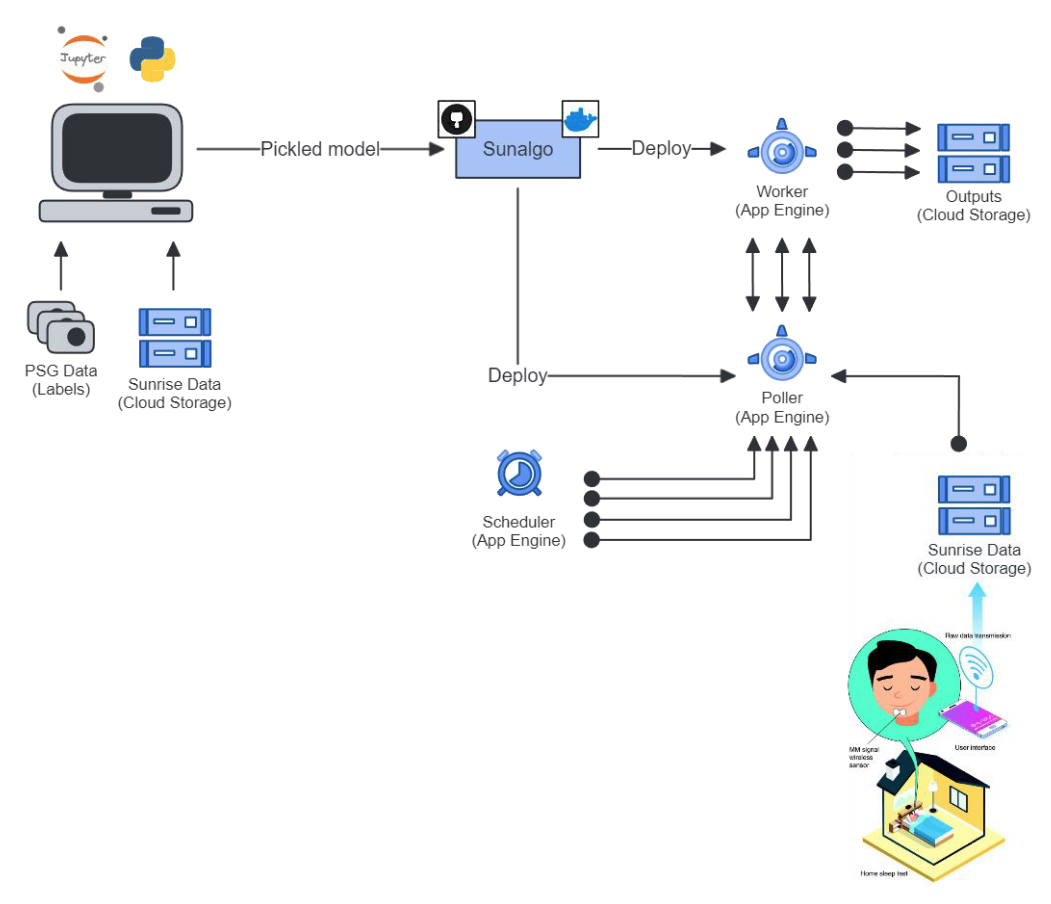
Briefly, we have two distinct “infrastructure” here.
The predictions service which was deployed on the google cloud with on App Engines. One worker service that was processing the recorded nights to generate predictions and clinical metrics. And one poller service that was constantly ping by a cron jobs to trigger the processing of new nights uploaded in our data lake (Google Storage).
The training infrastructure consisted of … one computer with a graphic card. Labeled data included nights recorded by polysomnography and the sunrise devices. They were stored kind of “everywhere”. On the cloud, on hard drives and on DropBox.
Speed of iteration
In software engineering and more broadly in active process, speed of iteration is critical. I am quite fan of the Boyd law of iteration:
Boyd decided that the primary determinant to winning dogfights was not observing, orienting, planning, or acting better. The primary determinant to winning dogfights was observing, orienting, planning, and acting faster. In other words, how quickly one could iterate.
To give you an example, to prepare the training data, the data scientist was running locally its code and was processing files one by one. We are talking about 2000 nights being individually processed to be cleant, extract clinical metadata and prepare the data in the right format for the training. Process was lasting between 30 seconds to maximum one and a half minute depending on the recorded night length.
In other words, this could take between one to three days. And after there was the training who took a couple more day. So it took them a bit more than a week of work to process, train evaluate and re-iterate.
Objectives
This serie of article will bring you through the different step of implementations made for our training platofrom and our production services. I will try to guide readers through the different steps and share some code snippets. Sunrise has been such a fullfilling experience for me. I am very proud about what we built in a year and a half and the speed and agility with which me moved toward our goals.
The serie will be structure as followed: